Research Topics
Deep Learning
Deep neural networks (DNNs) dramatically improve the accuracy of machine learning applications such as object detection and speech recognition that need the intelligence of human. In Design Automation Laboratory, we conduct research in various aspects of deep learning, from algorithms to hardware/software architectures.
Deep Neural Networks based on Stochastic Computing
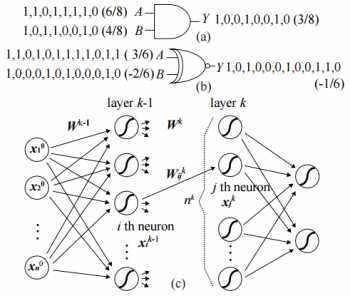
Compared with other machine learning techniques, DNNs typically require a lot more computations due to many layers and many neurons comprising the network. Moreover, the industrial and academic needs tend to increase the size and complicate the topology of DNNs. Because of this, using high performance computers with accelerators such as GPUs and/or clustering a bunch of machines is regarded as a practical solution to implementing DNNs. Considering, however, that machine learning has also been rapidly adopted in mobile and embedded systems such as self-driving car and patient data analysis with limited resources, researchers have paid great attention to finding possible ways of efficiently executing DNNs including minimizing the required precision and reducing the size of network.
In contrast to those studies based on conventional binary arithmetic computing, we conduct research and development in a different type of computing called stochastic computing (SC) for higher efficiency. SC can implement a circuit with smaller hardware footprint, lower power, and shorter critical path delay compared with conventional binary logic. It also has advantages in error tolerance and bit-level parallelism. Our research focuses on developing architectures and inference/learning methods to effectively apply stochastic computing to deep neural network implementations.
Representative Publications:
- Kyounghoon Kim, Jungki Kim, Joonsang Yu, Jungwoo Seo, Jongeun Lee, and Kiyoung Choi, “Dynamic energy-accuracy trade-off using stochastic computing in deep neural networks,” Design Automation Conference, pp. 124:1-124:6, Jun. 2016.
- Kyounghoon Kim, Jongeun Lee, and Kiyoung Choi, “An energy-efficient random number generator for stochastic circuits,” Asia and South Pacific Design Automation Conference, pp. 256-261, Jan. 2016.
Spiking Neural Network
A spiking neural network (SNN) is the third generation of an artificial neural network, where each neuron keeps a small state and delivers information in the form of spikes. Compared to conventional artificial neural networks, SNNs resemble biological neurons more closely and have potential to perform more efficiently than conventional fixed-point based neural networks. Research has been conducted from both academia and industry, including SpiNNaker (University of Manchester) and TrueNorth (IBM) projects. We explore efficient design of spiking neural network systems from hardware architectures to algorithmic approaches.
Hardware Accelerators for Deep Learning
Due to the massive amounts of computation in state-of-the-art DNN models, both academia and industry have actively studied specialized hardware architectures for accelerating deep neural network execution. For example, Google announced the use of their hardware accelerator for DNN inference called Tensor Processing Unit (TPU); Intel announced plans to support efficient DNN execution in their Xeon Phi products based on Nervana’s DNN accelerator design; a series of hardware accelerator designs have appeared in recent computer architecture conferences.
We study high-performance and energy-efficient hardware implementations of deep learning algorithms. Our goal is to develop hardware accelerators for deep learning algorithms, efficient distribution schemes for scalability, and system-/application-level support to ease the application of such hardware accelerators.
Memory Systems
As data-intensive applications become more and more important, the memory hierarchy has been considered as the key component that can determine the efficiency of a computer system. The memory hierarchy consists of multiple levels of memory from on-chip caches to main memory and storage, each with different performance-capacity-power trade-offs. In Design Automation Laboratory, we study each level of the memory hierarchy to improve its performance, energy efficiency, and reliability so that future computer systems can process large amounts of data more efficiently.
STT-RAM Caches
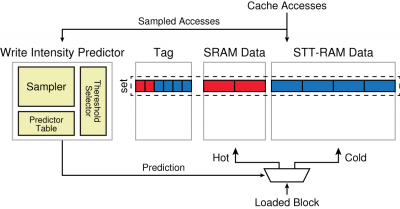
Spin-Transfer Torque RAM (STT-RAM) is a new non-volatile memory technology that can provide much lower static power and higher density than conventional charge-based memory (e.g., SRAM). Such characteristics are desirable to construct very large on-chip caches in an energy-/area-efficient way. However, compared to SRAM caches, STT-RAM caches exhibit inefficient write operations, which can potentially offset the energy benefit of STT-RAM.
We have explored energy-efficient and scalable on-chip cache design based on STT-RAM. The primary objective is to mitigate the impact of high write energy of STT-RAM while utilizing it as on-chip caches. Our approaches are mainly to modify the on-chip cache architecture in a way to reduce the amount of STT-RAM writes.
Representative Publications:
- Junwhan Ahn, Sungjoo Yoo, and Kiyoung Choi, “Prediction hybrid cache: An energy-efficient STT-RAM cache architecture,” IEEE Transactions on Computers, vol. 65, no. 3, pp. 940-951, Mar. 2016.
- Namhyung Kim, Junwhan Ahn, Woong Seo, and Kiyoung Choi, “Energy-efficient exclusive last-level hybrid caches consisting of SRAM and STT-RAM,” IFIP/IEEE International Conference on Very Large Scale Integration, pp. 183-188, Oct. 2015.
- Junwhan Ahn and Kiyoung Choi, “LASIC: Loop-aware sleepy instruction caches based on STT-RAM technology,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 22, no. 5, pp. 1197-1201, May 2014.
- Junwhan Ahn, Sungjoo Yoo, and Kiyoung Choi, “DASCA: Dead write prediction assisted STT-RAM cache architecture,” International Symposium on High Performance Computer Architecture, pp. 25-36, Feb. 2014.
Processing-in-Memory
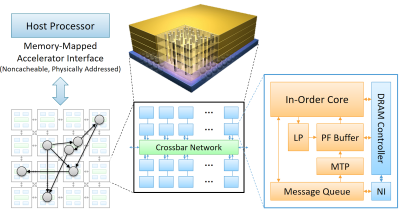
With the advent of big-data applications, the memory bandwidth requirements of data-intensive computing systems have continuously increased. However, conventional main memory technologies based on narrow off-chip channels (e.g., DDR3/4) are not enough to fulfill such high demand, mainly due to the limited off-chip bandwidth caused by CPU pin count limitations. Such memory bandwidth bottleneck has been exacerbated in the past few years due to the architectural innovations that can greatly improve the computation speed (e.g., chip multiprocessors, hardware accelerators). This motivates the need for a new computing paradigm that can fundamentally overcome the memory bandwidth bottleneck of conventional systems.
For this purpose, we conduct research in designing processing-in-memory (PIM) systems, where a portion of computation in applications is offloaded to in-memory computation units. PIM can not only provide very high memory bandwidth to in-memory computation units but also realize scalable memory bandwidth without being limited by CPU pin counts. Our research mainly focuses on architectures and programming models for PIM systems targeted for data-intensive applications and aims at providing high performance and high energy efficiency with an intuitive programming model.
Representative Publications:
- Junwhan Ahn, Sungjoo Yoo, and Kiyoung Choi, “AIM: Energy-efficient aggregation inside the memory hierarchy,” ACM Transactions on Architecture and Code Optimization, vol. 13, no. 4, pp. 34:1-34:24, Oct. 2016.
- Jinho Lee, Jung Ho Ahn, and Kiyoung Choi, “Buffered compares: Excavating the hidden parallelism inside DRAM architectures with lightweight logic,” Design, Automation and Test in Europe, Mar. 2016.
- Junwhan Ahn, Sungpack Hong, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi, “A scalable processing-in-memory accelerator for parallel graph processing,” International Symposium on Computer Architecture, pp. 105-117, Jun. 2015.
- Junwhan Ahn, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi, “PIM-enabled instructions: A low-overhead, locality-aware processing-in-memory architecture,” International Symposium on Computer Architecture, pp. 336-348, Jun. 2015.
Reconfigurable Multiprocessor System-on-Chip
We conduct research and development in reconfigurable MP-SoC structures with aims to provide flexibility and extensibility to satisfy the needs of designers and users of embedded systems. DAL has been selected as a National Research Laboratory (NRL) by the Korean Ministry of Education, Science and Technology in 2008.
Configurable Processor Design
We develop a configurable processor for application specific optimization and flexibility. This includes the basic processor, instruction extension methodology, cost/power minimization methodology, and a software development environment.
Representative Publications:
- Junwhan Ahn and Kiyoung Choi, “Isomorphism-aware identification of custom instructions with I/O serialization,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 32, no. 1, pp. 34-46, Jan. 2013.
- Di Wu, Junwhan Ahn, Imyong Lee, and Kiyoung Choi, “Resource-shared custom instruction generation under performance/area constraints,” International Symposium on System-on-Chip, Oct. 2012.
- Junwhan Ahn, Imyong Lee, and Kiyoung Choi, “A polynomial-time custom instruction identification algorithm based on dynamic programming,” Asia and South Pacific Design Automation Conference, pp. 573-578, Jan. 2011.
- Imyong Lee, Dongwook Lee, and Kiyoung Choi, “Memory operation inclusive instruction-set extensions and data path generation,” IEEE International Conference on Application-Specific Systems, Architectures, and Processors, pp. 383-390, Jul. 2007.
Reconfigurable Computing Module Design
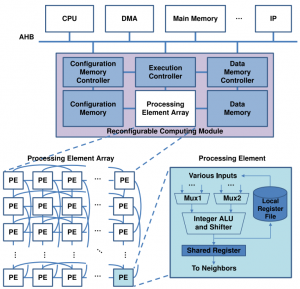
Future applications will require higher levels of concurrency for faster data processing, and more flexibility to run various kinds of tasks. To meet these requirements, we develop an RCM (Reconfigurable Computing Module) with a two-dimensional array of processing elements. These will include RCM-based floating-point operations, so that it can support 3D applications as well as video applications.
Representative Publications:
- Kyuseung Han, Junwhan Ahn, and Kiyoung Choi, “Power-efficient predication techniques for acceleration of control flow execution on CGRA,” ACM Transactions on Architecture and Code Optimization, vol. 10, no. 2, pp. 8:1-8:25, May 2013.
- Ganghee Lee, Kiyoung Choi, and Nikil D. Dutt, “Mapping multi-domain applications onto coarse-grained reconfigurable architectures,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 30, no. 5, pp. 637-650, May 2011.
- Kiyoung Choi, “Coarse-grained reconfigurable array: Architecture and application mapping,” IPSJ Transactions on System LSI Design Methodology, vol. 4, no. pp. 31-46, Feb. 2011.
- Dongwook Lee, Manhwee Jo, Kyuseung Han, and Kiyoung Choi, “FloRA: Coarse-grained reconfigurable architecture with floating-point operation capability,” International Conference on Field-Programmable Technology, pp. 376-379, Dec. 2009.
On-chip Communication Design
To meet the high bandwidth demands and large number of processors, we study several communication architectures, especially bus matrix and network-on-chip. Additionally, since memory architecture cannot be separated from the communication architecture, we study new methodologies to co-design them.
Representative Publications:
- Jinho Lee, Kyungsu Kang, and Kiyoung Choi, “REDELF: An energy-efficient deadlock-free routing for 3D NoCs with partial vertical connections,” ACM Journal on Emerging Technologies in Computing Systems, vol. 12, no. 3, pp. 26:1-26:22, Jan. 2015.
- Jinho Lee, Moo-Kyoung Chung, Yeon-Gon Cho, Soojung Ryu, Jung Ho Ahn, and Kiyoung Choi, “Mapping and scheduling of tasks and communications on many-core SoC under local memory constraint,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 32, no. 11, pp. 1748-1761, Nov. 2013.
- Hanmin Park and Kiyoung Choi, “Position-based weighted round-robin arbitration for equality of service in many-core network-on-chips,” International Workshop on Network on Chip Architectures, pp. 51-56, Dec. 2012.
- Dongwook Lee, Sungjoo Yoo, and Kiyoung Choi, “Entry control in network-on-chip for memory power reduction,” International Symposium on Low Power Electronics and Design, pp. 171-176, Aug. 2008.
MP-SoC Optimization and Programming
Based on the application and the MP-SoC platform, the designer must determine the number and types of processors to be integrated into the system. This is crucial to the system’s performance, cost, and power consumption. We study communication architecture generation methods to meet these requirements. We also study methods for describing the application, implementing the system, and verifying the implementation.
Representative Publications:
- Junhee Yoo, Sungjoo Yoo, and Kiyoung Choi, “Topology/floorplan/pipeline co-design of cascaded bus,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 17, no. 8, pp. 1034-1047, Aug. 2009.
- Yongjin Ahn, Keesung Han, Ganghee Lee, Hyunjik Song, Junhee Yoo, Kiyoung Choi, and Xingguang Feng, “SoCDAL: System-on-Chip Design AcceLerator,” ACM Transactions on Design Automation of Electronic Systems, vol. 17, no. 1, pp. 1-38, Jan. 2008.